Lifecycle Policies for Long Term Use¶
In SEAL Elastic Stack, the predefined lifecycle policies allow the data to be stored for at most 365 to 395 days. Some cases, e. g. accounting or audit data, require a longer storage period and an efficient method to search through the data.
Hint - snapshots of indices
You may make snapshots of indices before these are automatically deleted by the lifecyle policy, see Elasticsearch Database Backup. But you need to restore the snapshots as indices first to be able to search through the data, see Restoring the Elasticsearch Database.
The Enterprise license of Elastic allows you to create searchable snapshots. In this case you do not need to restore any snapshot.
You have to decide which license model you want to use, depending on how fast the reading access to the data has to be and how much disc space is available.
Configuration Samples¶
The following examples show the configuration for storage periods of 2 to 5 years. In order to keep the examples more comprehensible, the examples use 400 days for 1 year, and accordingly 800 days for 2 years and 2000 days for 5 years.
The specification of the time units corresponds to the following description: Time units.
You can easily adjust the examples for audit data or other Elasticsearch indices.
Literature - index lifecycle policies
For a complete description of the configuration of lifecycle policies for indices, see ILM: Manage the index lifecycle.
... for a 2 Years Storage Period¶
Example 1 - storing accounting data for 2 years with the quickest possible availability
This is granted during the hot phase of a lifecycle policy. In this example the hot phase takes 800 days, before indices are finally deleted.
PUT _ilm/policy/seal-plossys-5-accounting
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"set_priority": {
"priority": 100
},
"rollover": {
"max_primary_shard_size": "10gb",
"max_age": "30d"
}
}
},
"delete": {
"min_age": "800d",
"actions": {
"delete": {
"delete_searchable_snapshot": true
}
}
}
}
}
}
... for a 5 Years Storage Period¶
Example 2 - storing accounting data for 5 years with the quickest possible availability and indices being finally deleted after 2000 days
PUT _ilm/policy/seal-plossys-5-accounting
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"set_priority": {
"priority": 100
},
"rollover": {
"max_primary_shard_size": "10gb",
"max_age": "30d"
}
}
},
"delete": {
"min_age": "2000d",
"actions": {
"delete": {
"delete_searchable_snapshot": true
}
}
}
}
}
}
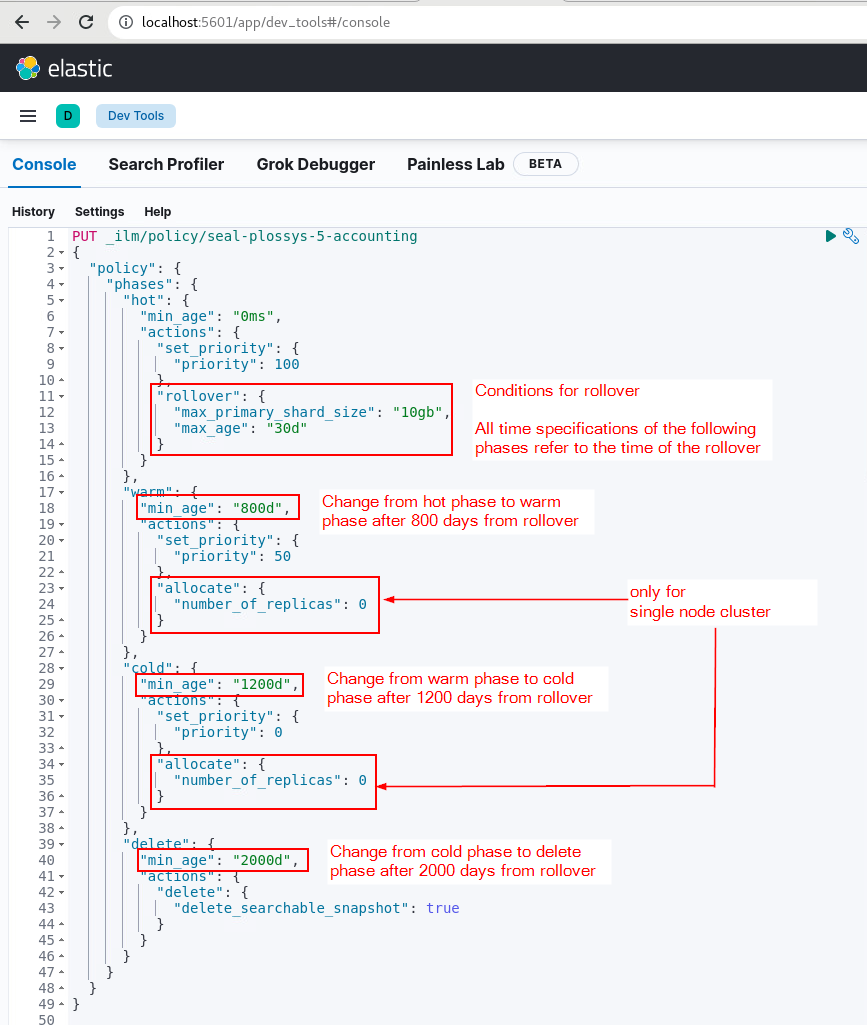
Example 3 - storing accounting data for 5 years with an efficient data search for the latest 2 years
The data are stored for 5 years. The search has to be efficient for the data of the latest 2 years, for data of the previous years the search can take longer. For this purpose you can configure a warm phase and/or a cold phase.
In this example the data remain at first in the hot phase for 800 days, then in the warm phase for the next 400 days and at last in the cold phase for another 800 days, before they are finally deleted after 2000 days.
PUT _ilm/policy/seal-plossys-5-accounting
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"set_priority": {
"priority": 100
},
"rollover": {
"max_primary_shard_size": "10gb",
"max_age": "30d"
}
}
},
"warm": {
"min_age": "800d",
"actions": {
"set_priority": {
"priority": 50
},
"allocate": {
"number_of_replicas": 0
}
}
},
"cold": {
"min_age": "1200d",
"actions": {
"set_priority": {
"priority": 0
},
"allocate": {
"number_of_replicas": 0
}
}
},
"delete": {
"min_age": "2000d",
"actions": {
"delete": {
"delete_searchable_snapshot": true
}
}
}
}
}
}
Caution - single node vs. cluster
You have to add the following lines in case of a single node cluster:
"allocate": {
"number_of_replicas": 0
}
The default of 1 would keep the systems from applying the lifecycle policies, as there is no second node on which the data copy can be stored.
You can leave out these lines in a real Elasticsearch cluster according to the JSON syntax.
Useful Details¶
-
Depending on the structure of the Elasticsearch cluster the above modifications have different effects. A single node cluster has only one node available, so the data cannot be transferred to the node with the most performant hardware.
-
As the data need to remain in direct access, according to the data throughput the PLOSSYS Output Engine system needs to have a great amount of disc space available, which you need to check regularly.
-
You can change the lifecycle policies any time via the DevTools Console. The changes effect existing indices with retrospective effect as long as they are linked to the policy.
-
When calling the
load-configconfiguration script lifecycle policies are only created, if they do not yet exist. They are never overwritten, not even in theoverwritemode. Thus customer-specific modifications remain untouched during an update. -
In the following screenshot the configuration options of the above examples are highlighted:
Glossary¶
-
hot phaseStore your most recent, most frequently-searched data in the hot tier. The hot tier provides the best indexing and search performance by using the most powerful, expensive hardware.
-
warm phaseMove data to the warm tier, if you are still likely to search it, but infrequently need to update it. The warm tier is optimized for search performance over indexing performance.
-
cold phaseMove data to the cold tier, if you are searching it less often and don’t need to update it. The cold tier is optimized for cost savings over search performance.