Safely Updating the Configuration of Ingest Pipelines¶
Ingest pipelines are used to modify data before they are stored in Elasticsearch. These modifications may include e. g. changing printer names to lower case, anonymizing data, and other.
This chapter provides a concept for safely updating ingest pipelines. Aim is to combine SEAL-specific and customer-specific pipelines in a way that allows the SEAL-pipelines to be updated without overwriting the customer-specific parts.
Implementation¶
Components¶
The concept includes the following components to assign an update-safe interface that embeds customer-specific pipelines to an index:
-
A component template to define the pipelines with.
-
An index template to which the component template is assigned.
If according to this index template a new index is created, the pipeline from the component template is linked to this index.
-
A Pipeline consisting of three sub-pipelines that are passed through successively.
-
The middle pipeline contains the SEAL-specific part and is named with the
workpostfix. -
The other two pipelines contain
beforeandafterinterfaces for customer-specific parts and are named accordingly with eitherbeforeorafterpostfixes.Besides these pipelines carry the
customkeyword in their names. Pipelines with this keyword in the name are only uploaded to Elasticsearch by theload-configscript, if they do not yet exist. This way only an initial SEAL version is uploaded that can be customized and will not be overwritten by later updates.You can configure customer-specific pipelines manually or via script, as you do when anonimizing pipelines.
-
All necessary components are provided in the form of .JSON snippets and uploaded to Elasticsearch by means of the load-config script.
If you execute the script in a new installation for the very first time, the components that need to be set up do not yet exist. Therefore all component templates and predefined pipelines are uploaded. Afterwards, especially in case of an update, the script uploads only components that are either allowed to be updated or forced to be updated using the overwrite mode:
-
Component Templates are always overwritten, i.e. you must not change the templates in a customer's installation. Otherwise the customization gets lost with the next update, because it is overwritten with the current SEAL version.
-
Customer-specific pipelines with
customin their name are only created. Afterwards theload-configscript does never overwrite them. Only if you delete the pilelines manually in the Kibana user interfade, they will be recreated according to the present JSON snippets. -
Other pipelines are always overwritten. These are the SEAL-specific pipelines that are to be replaced by improved versions during an update.
-
Index templates are always overwritten. You do not need the
overwritemode any more.
In Case of Errors¶
For all pipelines, you can use a processor for the error handling. The current procedure stipulates that you move the affected record into another index, commomly called dead-letter-index.
Filebeat uses the seal-plossys-5-unmapped index for this purpose. Use this one here as well.
Troubleshooting: List of Passed Through Pipelines¶
All new pipelines for PLOSSYS Output Engine have been enhanced by a mechanism, so that each one adds its indentifier to the pipelines_passed_through field:
-
The previous SEAL-specific
seal-plossys-5-lowercase-printerspipeline adds itslowercase-printersindentifier.. -
The new SEAL-specific
seal-plossys-5-avoid-type-mismatchespipeline adds itsavoid-type-mismatchesindentifier.
This allows a quick check, whether the affected pipeline has been passed through, if an error occurs.
The order of the entries corresponds to the order of passing through the pipelines.
| Index | Inhalt von pipelines_passed_through |
|---|---|
seal-plossys-5-log |
log-toplevel, log-before, log-work, lowercase-printers, avoid-type-mismatches, log-after |
seal-plossys-5-accounting |
accounting-toplevel, accounting-before, accounting-work, accounting-after |
seal-plossys-5-audit |
audit-toplevel |
seal-plossys-5-statistics |
statistics-toplevel |
Below you will find screenshots matching the values of the above table:
-
standard logging index for PLOSSYS Output Engine,
seal-plossys-5-log: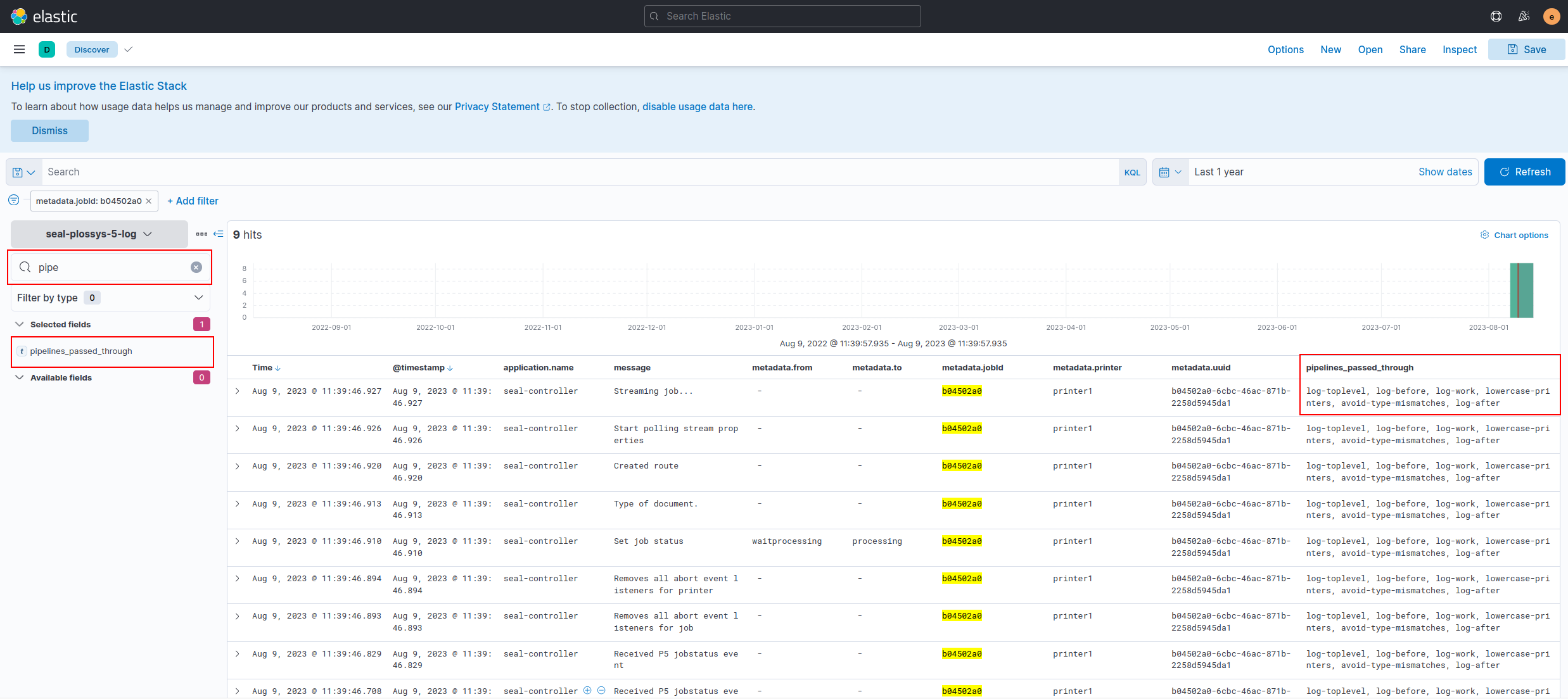
-
accounting index for PLOSSYS Output Engine,
seal-plossys-5-accounting: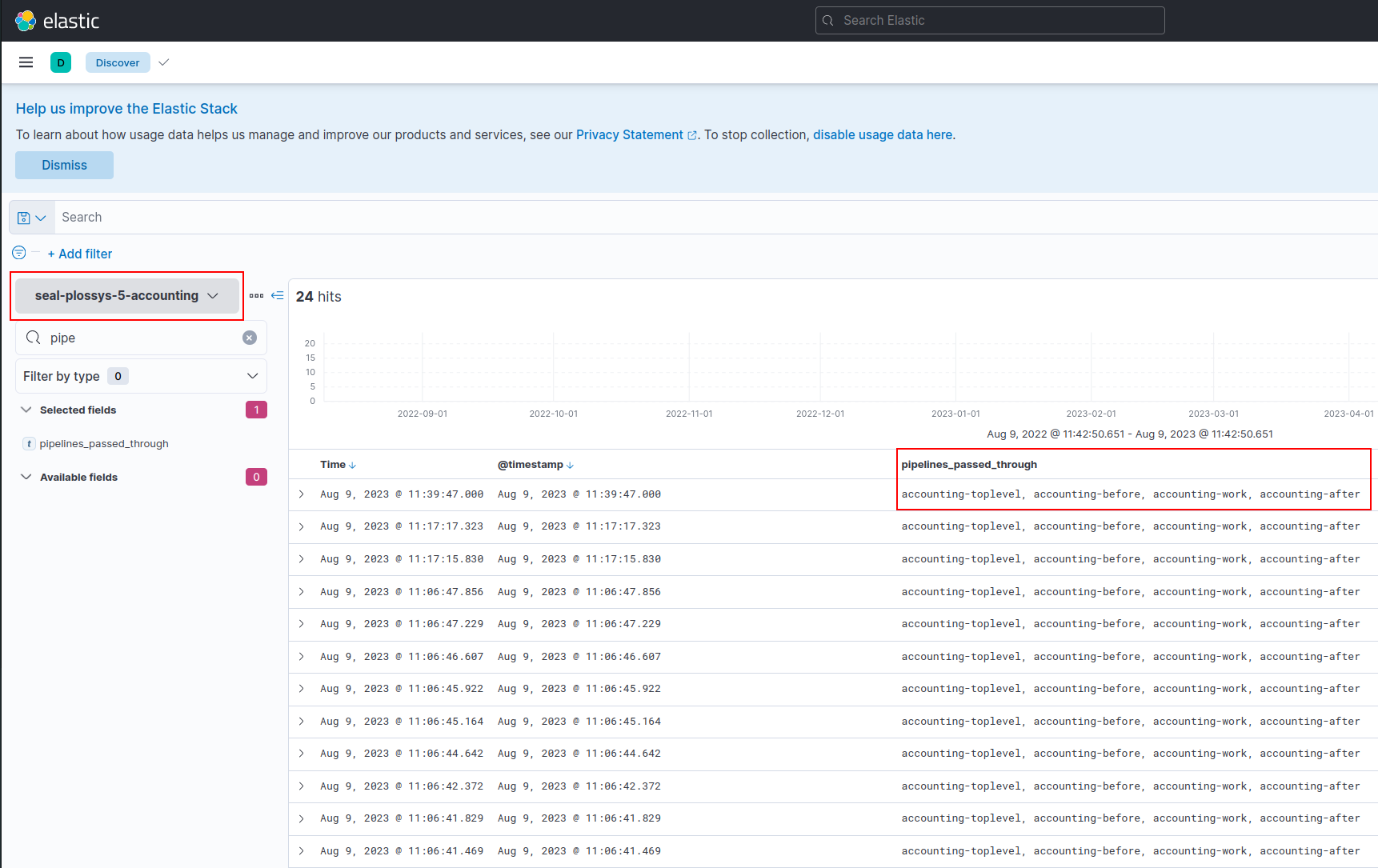
-
audit index for PLOSSYS Output Engine,
seal-plossys-5-audit: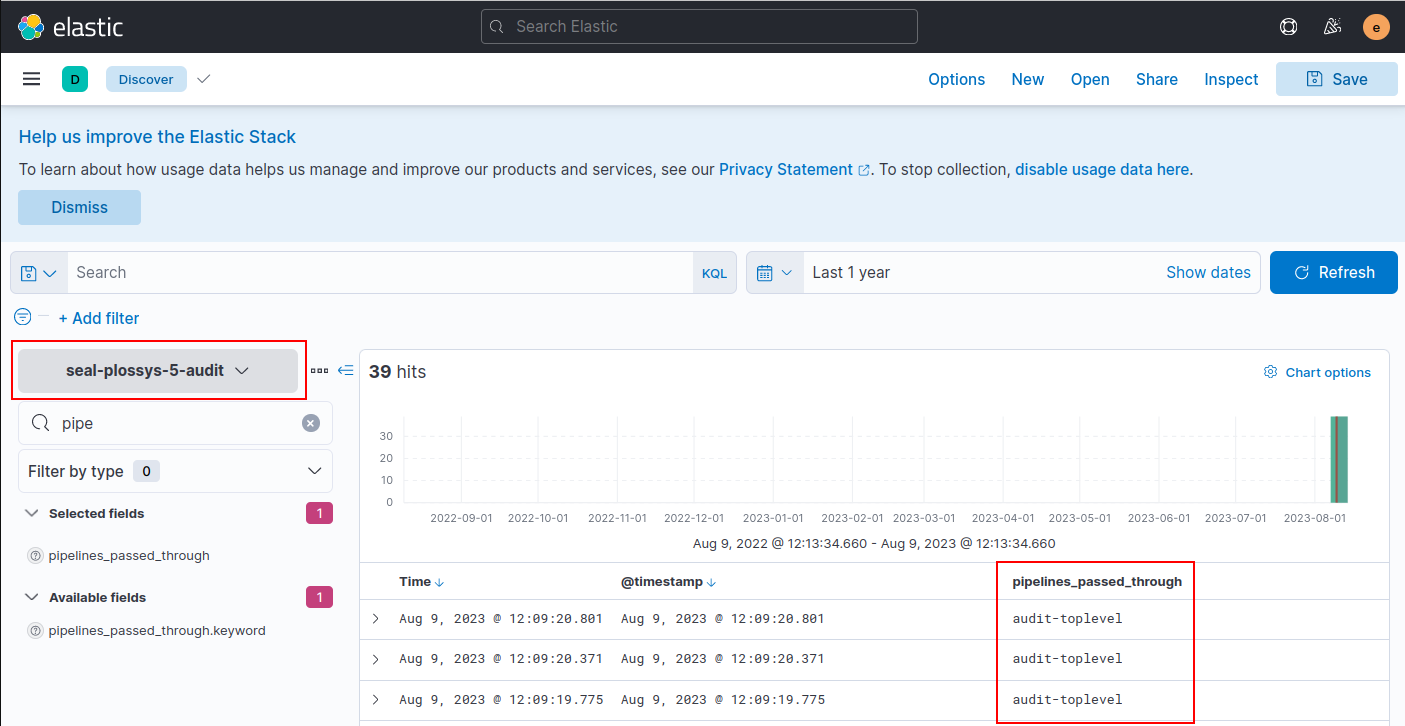
-
statistics index for PLOSSYS Output Engine,
seal-plossys-5-statistics: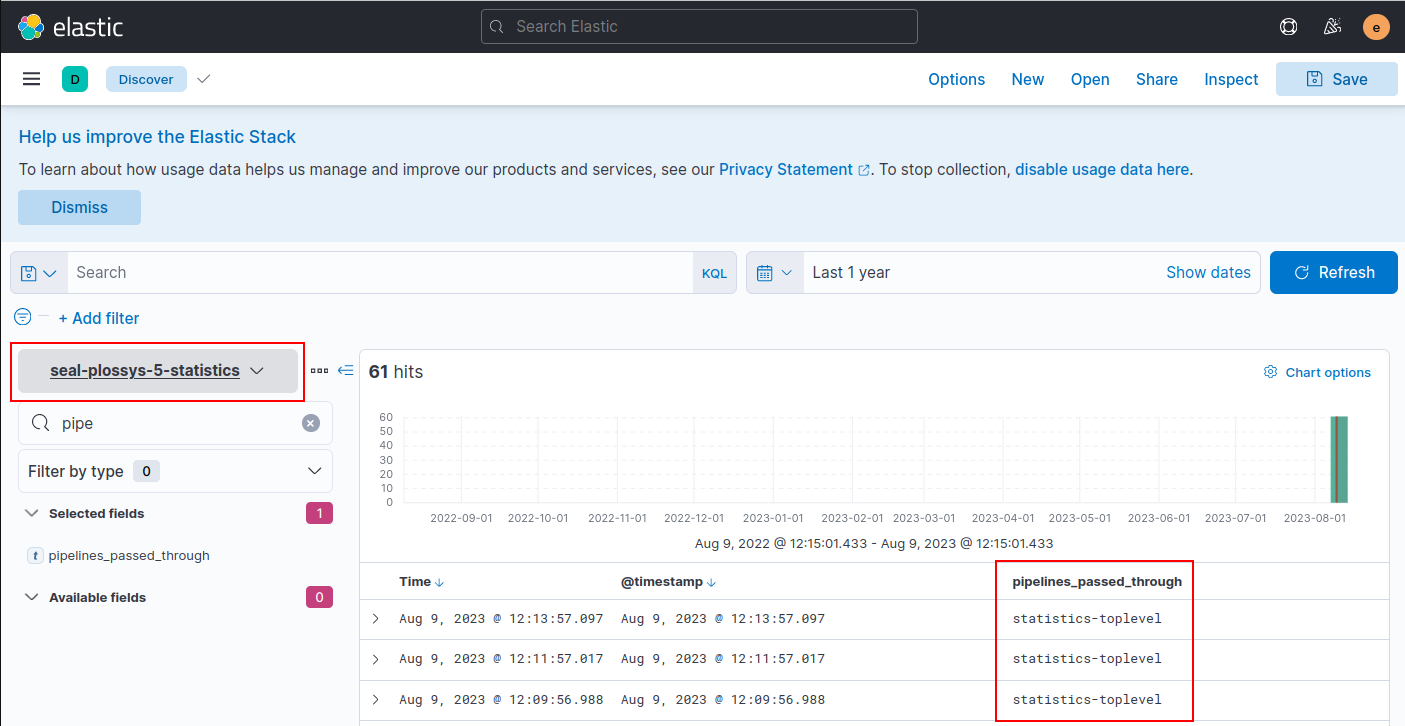
Deeper Insights¶
The new pipeline concept has been implemented only where it was needed, i. e. in
-
the standard logging index for PLOSSYS Output Engine,
seal-plossys-5-log -
the accounting index for PLOSSYS Output Engine,
seal-plossys-5-accountingHere we do not yet have a SEAL-specific pipeline, but there are customer-specific adjustments concerning an anonymizing pipeline. The passing through of this pipeline must not be removed by an update.
The concept has been rudimentarily prepared for
-
the audit index
-
the statistics index
If you need to set up an ingest pipeline for another index, e. g. PLOSSYS Distribution Engine/DPF , SEAL Operator, ..., we recommend you use the described pipeline configuration as template. You should structure the nesting of the base pipelines and the addition of the pipeline identifier in the pipelines_passed_through field in the same way as described above.
The following examples are provided in the configuration directory as JSON snippets for load-config.
The Pipelines¶
-
All pipelines are set up in a way that in case of error the data are moved to the
seal-plossys-5-unmappedindex. -
All processor are usually set up in a way that an error that occurred is not to be ignored.
The Top Pipeline¶
The description uses the following pipeline as example: seal-plossys-5-accounting
The top pipeline
-
looks the same for any index, except of the names.
-
skips the corresponding processor, if you specify
"false"for the"if"item. -
contains the pipelines below that are passed through in the given order.
-
is defined in
configuration/seal-plossys-5/pipeline/accounting.json:{ "description": "Default toplevel pipeline for corrections to data used as input for seal-plossys-5-accounting index", "processors": [ { "append": { "field": "pipelines_passed_through", "value": [ "accounting-toplevel" ], "if": "true", "description": "add pipeline accounting-toplevel" } }, { "pipeline": { "name": "seal-plossys-5-accounting-custom-before", "if": "true", "tag": "before" } }, { "pipeline": { "name": "seal-plossys-5-accounting-work", "if": "true", "tag": "work" } }, { "pipeline": { "name": "seal-plossys-5-accounting-custom-after", "if": "true", "tag": "after" } } ], "on_failure": [ { "set": { "field": "_index", "value": "seal-plossys-5-unmapped" } } ] }
Customer-Specific "before" Pipeline¶
The description uses the following pipeline as example: seal-plossys-5-accounting-custom-before
The customer-specific before pipeline
-
is passed through by the SEAL-specific pipeline.
-
is not overwritten by an update, because of the
customkeyword in its name. -
is able to handle things like flags that control the SEAL-specific part, as this pipeline is the first one thas is passed through.
-
contains the customer-specific, installable
anonymizationpipeline in the example.-
As the
"if"item is set to"false", a pipeline of this name does not have to exist. It does not cause an error, because the processor is skipped. -
As soon as you have configured your customer-specific
anonymizationpipeline, you can activate the flag by setting the"if"item to"true".
-
-
is defined in
configuration/seal-plossys-5/pipeline/accounting-custom-before.json:{ "description": "Custom pipeline for corrections to data before indispensable pipeline seal-plossys-5-accounting-work", "processors": [ { "append": { "field": "pipelines_passed_through", "value": [ "accounting-before" ], "if": "true", "description": "add pipeline accounting-before" } }, { "pipeline": { "name": "anonymization", "if": "false" } } ], "on_failure": [ { "set": { "field": "_index", "value": "seal-plossys-5-unmapped" } } ] }
SEAL-Specific Pipeline¶
The description uses the following pipeline as example: seal-plossys-5-accounting-work
The SEAL-specific pipeline
-
contains the processing steps, which SEAL requires for the data consistency and other things.
-
is replaced by the current version during an update.
-
contains a list of processors, that generally are to be passed through.
In most cases the type of incoming data decides, whether a processor is passed through or not. It is also possible to trigger other things, e. g. retrieving flags defined in the
beforepipeline. -
is defined in
configuration/seal-plossys-5/pipeline/accounting-work.json:{ "description": "Pipeline for corrections to data used as input for seal-plossys-5-accounting index", "processors": [ { "append": { "field": "pipelines_passed_through", "value": [ "accounting-work" ], "if": "true", "description": "add pipeline accounting-work" } }, { "rename": { "field": "accounting.principals.deviceID", "target_field": "accounting.principals.endpoint", "ignore_missing": true, "tag": "rename_deviceID_to_endpoint", "description": "rename deprecated deviceID to endpoint" } }, { "pipeline": { "name": "not-existing-pipeline-example", "if": "false" } } ], "on_failure": [ { "set": { "field": "_index", "value": "seal-plossys-5-unmapped" } } ] }
Customer-Specific "after" Pipeline¶
The description uses the following pipeline as example: seal-plossys-5-accounting-custom-after
The customer-specific after pipeline
-
is passed through after the SEAL-specific pipeline.
-
is not overwritten by an update, because of the
customkeyword in its name. -
can be controlled by corresponding settings, i. e. the processors are passed through always or depending on the type of the incoming data or flags in the previous pipelines.
-
is defined in
configuration/seal-plossys-5/pipeline/accounting-custom-after.json:{ "description": "Custom pipeline for corrections to data after indispensable pipeline seal-plossys-5-accounting-work", "processors": [ { "append": { "field": "pipelines_passed_through", "value": [ "accounting-after" ], "if": "true", "description": "add pipeline accounting-after" } }, { "pipeline": { "name": "not-existing-pipeline-example", "if": "false" } } ], "on_failure": [ { "set": { "field": "_index", "value": "seal-plossys-5-unmapped" } } ] }
The Templates¶
Component templates are parts of the configuration that are used by index templates.
Component Template for an Accounting Pipeline¶
The description uses the following pipeline as example: seal-plossys-5-accounting-pipeline
The seal-plossys-5-accounting top pipeline
-
is integrated under
default_pipelineitem as default pipeline. The default pipeline is passed through early enough to allow data sets to be moved into another index. -
is defined in
configuration/seal-plossys-5/index-template/components/accounting-pipeline.json:{ "template": { "settings": { "index": { "default_pipeline": "seal-plossys-5-accounting" } } } }
Integrating the Component Templates into the Index Template¶
The description uses the following pipeline as example: seal-plossys-5-accounting
-
This is just an excerpt of the actual JSON snippet.
-
The component template is specified under the
composed_ofitem inconfiguration/seal-plossys-5/index-template/accounting.json:{ "index_patterns": [ "seal-plossys-5-accounting-*" ], "composed_of": ["seal-plossys-5-accounting-pipeline"], "priority": 160, ... }
List of Passed Through Pipelines¶
| Index | Content of pipelines_passed_through |
Hint |
|---|---|---|
seal-plossys-5-accounting |
accounting-toplevel, accounting-before, accounting-work, accounting-after | |
seal-plossys-5-accounting |
accounting-toplevel, accounting-before, anonymization, accounting-work, accounting-after | Idea for the future: An anonymizing pipeline installed and configured so that it adds its identifier here. |